반응형
기술적인 '그릇(레이크하우스)'에서 한 걸음 더 들어가, 실제 요리 과정에서 발생하는 가장 골치 아픈 문제이자 데이터 엔지니어의 실력을 판가름하는 척도, 데이터 치우침(Data Skew) 현상에 대해 딥다이브 해보겠습니다.
분산 처리 시스템에서 "왜 내 작업은 99%에서 멈춰서 안 끝날까?"라는 의문이 든다면 100% 이 녀석이 범인입니다.
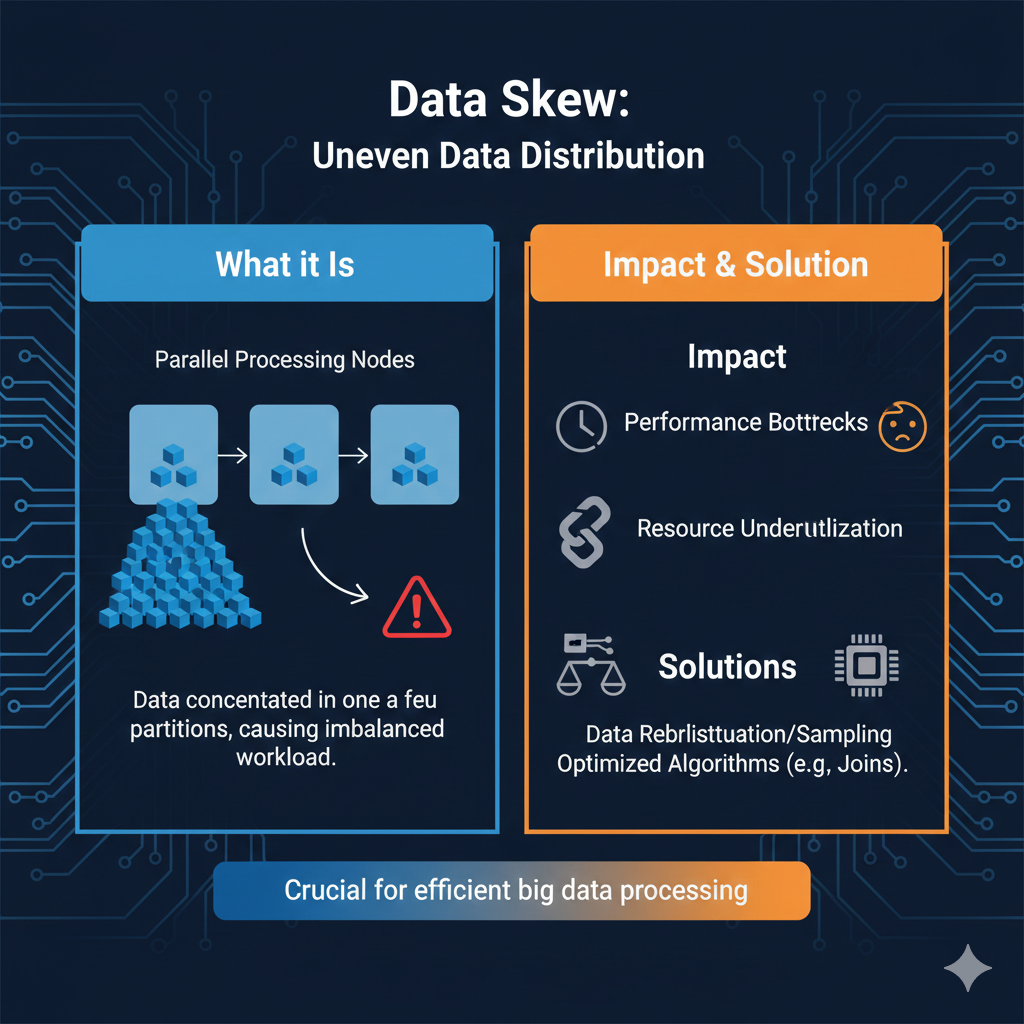
⚖️ 데이터 치우침(Data Skew): "한 놈만 죽어라 일하는 불공평한 주방"
분산 처리(Spark 등)의 핵심은 데이터를 여러 요리사(Executor)에게 골고루 나눠주는 것입니다. 하지만 특정 조건 때문에 특정 요리사에게만 업무가 몰리는 현상이 발생하는데, 이게 바로 Data Skew입니다. 나머지 99명의 요리사는 자기 일을 다 끝내고 노는데, 단 1명이 남은 산더미 같은 일을 하느라 전체 작업 시간이 그 1명에게 맞춰지는 비효율의 극치를 보여주죠.
1. 왜 발생하는가? (The Root Cause)
주로 데이터를 합치거나(Join), 그룹화(GroupBy)할 때 발생합니다.
- 불균등한 키 분포: 예를 들어 전 세계 결제 데이터를 '국가별'로 쪼갰다고 합시다. '투발루' 담당 요리사는 할 일이 없는데, '미국'이나 '중국' 담당 요리사는 데이터가 너무 많아서 터져버리는 식입니다.
- Null 값의 습격: 특정 컬럼에
Null값이 비정상적으로 많을 때, Spark는 기본적으로 이Null들을 하나의 파티션으로 몰아넣는 경향이 있습니다.
2. 구체적인 해결 전략 (The Engineering Solutions)
이 문제를 해결하는 방법은 크게 5가지 기술적 트릭이 있습니다.
① Salting (솔팅: 소금 뿌리기)
가장 정석적이고 강력한 방법입니다. 편중된 키 뒤에 임의의 난수(Salt)를 붙여서 강제로 데이터를 흩뜨리는 기법입니다.
- 방법: '미국'이라는 키가 너무 많다면, '미국_1', '미국_2', '미국_3'으로 이름을 바꿔서 여러 요리사에게 나눠줍니다. 나중에 계산이 끝나고 다시 '미국'으로 합치면 되죠. 뭉쳐 있는 소금 덩어리를 잘게 부수는 것과 같습니다.
② Broadcast Join (브로드캐스트 조인)
두 테이블을 합칠 때(Join), 한쪽 테이블이 충분히 작다면(예: 국가 코드 마스터 테이블) 사용합니다.
- 방법: 작은 테이블을 모든 요리사의 메모리에 통째로 복사해서 뿌려버립니다. 이렇게 하면 데이터를 섞는(Shuffle) 과정 없이 각자 자기 자리에서 바로 조인할 수 있어 치우침 자체가 발생하지 않습니다.
③ Adaptive Query Execution (AQE: 적응형 쿼리 실행)
Spark 3.0부터 도입된 인공지능 같은 기능입니다.
- 방법: Spark가 실행 중에 "어? 특정 파티션이 너무 큰데?"라고 판단하면, 런타임에 알아서 그 파티션을 잘게 쪼개거나 적절한 조인 전략으로 변경합니다. 사용자가 일일이 설정하지 않아도 Spark가 스스로 주방 상황을 보고 판단하는 거죠.
④ Filtering & Explicit Partitioning
- 방법:
Null값이 문제라면 조인 전에Null데이터를 미리 필터링해서 따로 처리하거나,repartition()함수를 써서 데이터가 특정 키에 몰리지 않게 무작위로 다시 섞어주는 방법입니다.
⑤ Isolated Processing (고립 처리)
- 방법: 치우침이 심한 상위 1%의 키(Heavy Hitters)만 따로 추출해서 별도의 로직으로 처리하고, 나머지 99%의 평범한 데이터와 나중에 합치는 방식입니다.
3. 실전 비유: "급식 배분 대작전"
- 상황: 전교생에게 돈까스를 나눠주는데, '1반' 학생만 500명이고 나머지 반은 20명씩입니다.
- Skew 발생: 1반 담당 배식대만 줄이 끝도 없이 길어지고 점심시간이 안 끝납니다.
- Salting 해결: 1반 학생들의 번표 뒤에 A, B, C를 붙여서 1반-A는 7번 배식대, 1반-B는 8번 배식대로 강제로 분산 수용합니다.
- Broadcast 해결: 모든 배식대에 "반별 보너스 점수표(작은 데이터)"를 한 장씩 미리 나눠줘서, 애들이 물어볼 때마다 본부에 확인하러 올 필요 없게 만듭니다.
4. 데이터 엔지니어의 디버깅 팁
나중에 Spark UI를 보실 때, Max Task Time과 Median Task Time의 차이를 꼭 확인하세요.
- 평균은 10초인데 최대 시간이 1시간이다? 100% Data Skew입니다.
- 이때 어떤 키가 범인인지 찾아서 Salting을 적용하는 순간, 전체 작업 시간이 1시간에서 1분으로 줄어드는 마법을 경험하시게 될 겁니다. 이게 바로 엔지니어의 '손맛'이죠! ㅎㅎㅎ
반응형
'1. 개발 > 1.4. 데이터 분석' 카테고리의 다른 글
| 카프카에 담긴 데이터를 가져다가 Spark로 요리할 때, 실시간으로 요리하는 '스트리밍(Streaming)' 처리는 어떻게 하는가? (0) | 2026.02.04 |
|---|---|
| 아파치 에어플로우(Apache Airflow) (0) | 2026.02.04 |
| 데이터 레이크하우스(Data Lakehouse) (0) | 2026.02.04 |
| 데이터 레이크(Data Lake)와 웨어하우스(DW) (0) | 2026.02.04 |
| 카프카(Kafka)라는 녀석에 대해 자세히 알려줘! (0) | 2026.02.03 |



