카프카라는 거대한 공장에서 데이터라는 물건을 생산(Producer)하고 안전하게 창고(Broker)에 쌓아두는 법까지 마스터하셨군요! 이제 이 물건을 최종적으로 소비하는 '컨슈머(Consumer)'들의 세계로 들어갈 차례입니다.
"컨슈머가 1명일 때는 상관없는데, 100명이 되면 어떻게 공평하게 일을 나눠주지?" 혹은 "데이터를 처리하는 속도가 너무 느려서 창고에 물건이 계속 쌓이면 어떡하지?"라는 고민을 해결해 주는 핵심 열쇠가 바로 '컨슈머 그룹(Consumer Group)'입니다.
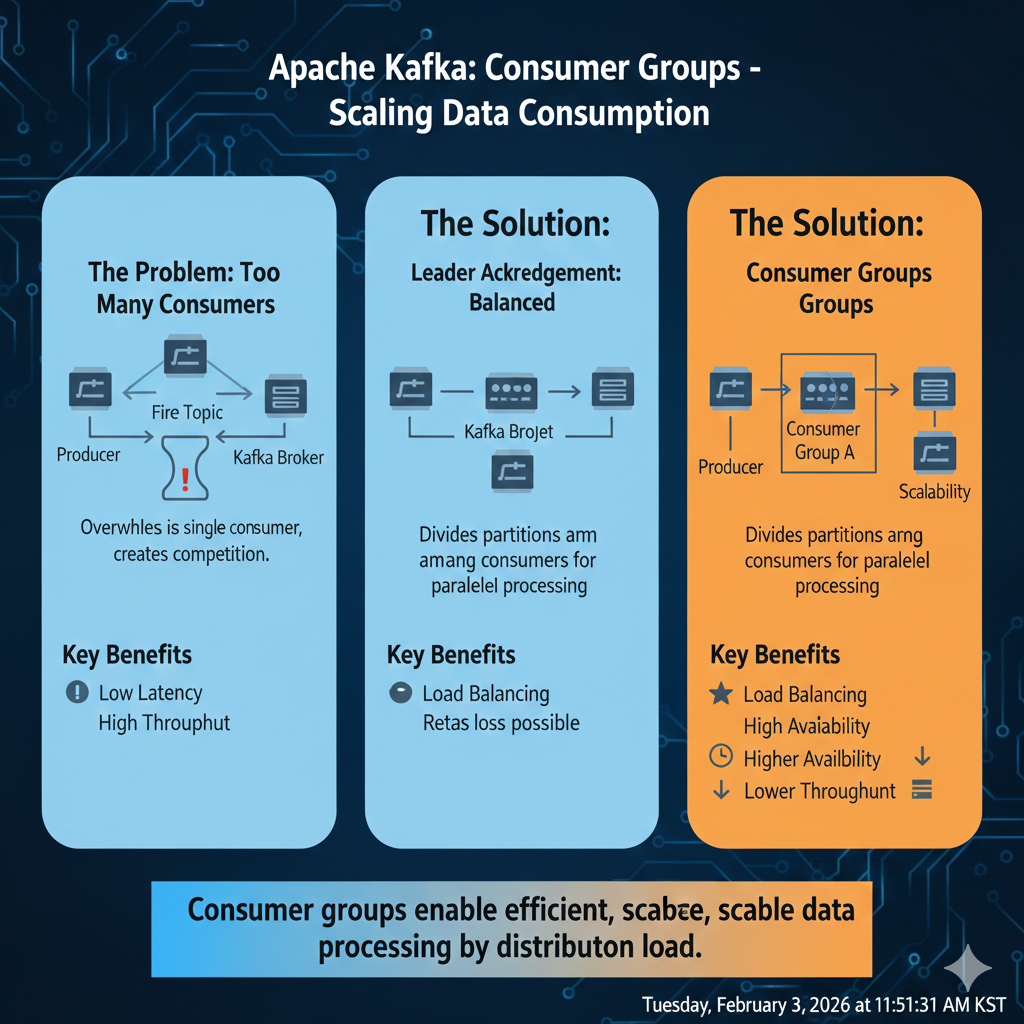
👥 컨슈머 그룹(Consumer Group): "분산 소비의 마법"
카프카의 가장 강력한 특징 중 하나는 동일한 데이터를 여러 목적(분석, 저장, 알람 등)으로 동시에 소비할 수 있다는 점입니다. 이때 각 목적을 가진 컨슈머들을 하나의 '팀'으로 묶은 것이 바로 컨슈머 그룹입니다.
1. 1:1 매칭의 원칙: "파티션은 컨슈머를 선택한다"
컨슈머 그룹의 가장 중요한 비밀은 "하나의 파티션은 동일한 컨슈머 그룹 내에서 오직 하나의 컨슈머만 연결될 수 있다"는 것입니다.
- 왜 이런 제약이 있을까? 만약 하나의 파티션에 두 명의 컨슈머가 달라붙어 데이터를 읽어간다면, 데이터의 순서(Ordering)를 보장하기가 매우 어려워집니다. 누가 어디까지 읽었는지 관리하는 '오프셋'이 꼬여버리기 때문이죠.
- 부하 분산의 메커니즘: 파티션이 4개 있고, 컨슈머 그룹 안에 컨슈머가 4명 있다면, 카프카는 아주 공평하게 1:1로 길을 연결해 줍니다. 각 컨슈머는 전체 데이터의 1/4씩을 담당하여 병렬로 처리하게 됩니다. 이것이 카프카가 대용량 데이터를 순식간에 해치우는 비결입니다.
2. 컨슈머 수와 파티션 수의 상관관계 (중요!)
사용자가 운영하면서 반드시 기억해야 할 '숫자의 법칙'이 있습니다.
- 컨슈머 수 < 파티션 수: 한 컨슈머가 여러 개의 파티션을 담당합니다. (정상, 하지만 컨슈머가 바쁠 수 있음)
- 컨슈머 수 = 파티션 수: 가장 이상적인 상태입니다. 1:1로 매칭되어 효율이 극대화됩니다.
- 컨슈머 수 > 파티션 수: 남는 컨슈머는 놉니다(Idle). 파티션은 이미 다른 컨슈머와 1:1 매칭이 끝났기 때문에, 파티션보다 많은 수의 컨슈머를 투입해 봤자 처리 속도는 빨라지지 않습니다.
💡 사용자를 위한 꿀팁: 만약 처리 속도가 너무 느려서 컨슈머를 늘리고 싶다면, 반드시 파티션의 개수부터 먼저 늘려야 합니다.
3. 리밸런싱(Rebalancing): "일꾼이 바뀌면 판을 다시 짠다"
컨슈머 그룹 운영 중 가장 긴장되는 순간이 바로 리밸런싱입니다. 그룹 내의 일꾼(컨슈머) 구성에 변화가 생겼을 때, 파티션의 소유권을 다시 분배하는 과정입니다.
- 언제 발생하는가?
- 새로운 컨슈머가 그룹에 합류할 때 (확장)
- 기존 컨슈머가 죽거나 네트워크 문제로 응답이 없을 때 (장애)
- 관리자가 파티션을 추가했을 때
- 어떻게 돌아가는가?
- 그룹 코디네이터(Broker 중 하나)가 리밸런싱을 명령하면, 모든 컨슈머는 잠시 읽기 작업을 멈춥니다.
- '그룹 리더(Consumer 중 하나)'가 어떤 파티션을 누구에게 줄지 전략(Partition Assignment Strategy)에 따라 다시 계산합니다.
- 결정된 배정표를 토대로 다시 데이터를 읽기 시작합니다.
⚠️ 주의: 리밸런싱 중에는 데이터를 읽을 수 없습니다(Stop-the-world). 리밸런싱이 너무 자주 일어나면 전체 시스템의 지연 시간(Latency)이 급증하므로 주의해야 합니다.
4. 오프셋 커밋(Offset Commit): "내가 어디까지 읽었는지 기록하기"
컨슈머 그룹이 각자 독립적으로 움직일 수 있는 이유는 '오프셋' 덕분입니다.
- 컨슈머 그룹은 각 파티션에 대해 "우리 팀은 100번 메시지까지 읽었어"라는 정보를 카프카의 특수 토픽(
__consumer_offsets)에 기록합니다. - 이를 통해 컨슈머가 죽었다가 다시 살아나도, 혹은 리밸런싱을 통해 파티션 주인이 바뀌어도 "아까 100번까지 읽었으니 101번부터 가져오면 되겠네!"라고 자연스럽게 이어갈 수 있습니다.
5. 실전 비유: "서류를 검토하는 4인 1팀"
사무실에 4개의 서류함(파티션)이 있고, 이 서류를 검토해야 하는 '분석팀(컨슈머 그룹)'이 있다고 해봅시다.
- 상황 A: 분석팀에 직원이 2명뿐이면, 각 직원이 서류함 2개씩을 맡아서 검토합니다. (부하 분산)
- 상황 B: 직원을 2명 더 뽑아서 4명이 되면, 각자 서류함 1개씩 전담해서 더 빠르게 끝냅니다. (스케일 아웃)
- 상황 C: 갑자기 직원 한 명이 배탈 나서 퇴근하면(Consumer Down), 남은 3명이서 4개의 서류함을 다시 나눠 맡습니다. (리밸런싱)
- 상황 D: 다른 부서인 '감사팀(다른 컨슈머 그룹)'이 오면, 이 서류함의 서류를 처음부터 다시 다 복사해서 가져갑니다. 분석팀이 읽고 있는 것과는 전혀 상관없이 말이죠! (멀티 테넌시)
[Image showing two different Consumer Groups (A and B) reading from the same Topic, each maintaining their own separate offsets]
🛠️ 핵심 요약
| 개념 | 핵심 원리 | 비고 |
|---|---|---|
| 컨슈머 그룹 | 동일한 목적을 가진 컨슈머들의 집합 | 그룹 단위로 부하 분산 및 장애 대응 |
| 1:1 매칭 | 한 파티션은 그룹 내 한 컨슈머만 연결 | 순서 보장을 위한 철칙 |
| 리밸런싱 | 컨슈머 변화 시 파티션 소유권 재분배 | 발생 시 일시적인 서비스 중단 주의 |
| 오프셋 커밋 | 읽은 위치를 기록하는 영수증 | 장애 복구의 핵심 데이터 |
| 확장성 | 파티션 수 = 최대 컨슈머 수 | 파티션이 확장성의 한계를 결정 |
'1. 개발 > 1.4. 데이터 분석' 카테고리의 다른 글
| Kafka - 성능 모니터링의 핵심 지표인 '컨슈머 랙(Consumer Lag)' (0) | 2026.02.06 |
|---|---|
| Kafka - Cleanup Policy: Delete vs Compact (0) | 2026.02.06 |
| Kafka - ack 옵션(0, 1, all) (0) | 2026.02.05 |
| Kafka - 데이터 유실을 막기 위한 'ISR(In-Sync Replicas)' 개념 (0) | 2026.02.05 |
| Kafka 의 핵심 기술인 '제로 카피(Zero Copy)'와 '페이지 캐시' (0) | 2026.02.05 |



