이제 데이터 아키텍처의 마지막 퍼즐 조각인 '비용 효율적인 데이터 저장'과 '멱등성 유지'라는 두 마리 토끼를 잡는 전략에 도달하셨군요! 🫡
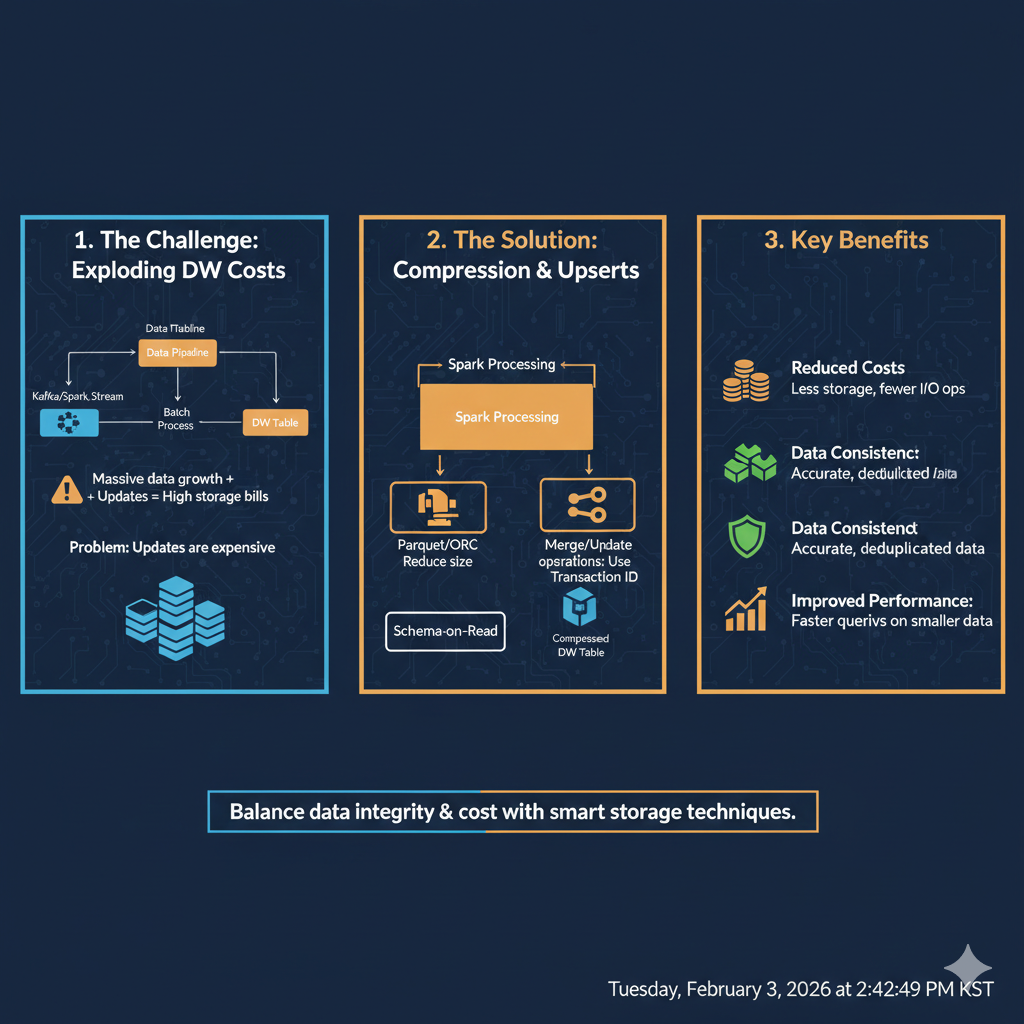
데이터 웨어하우스(DW)는 성능이 뛰어난 만큼 저장 비용이 일반 스토리지(S3)보다 훨씬 비쌉니다. 모든 데이터를 DW에 무지성(?)으로 쌓다가는 수익금이 AWS나 구글 클라우드로 다 빠져나갈 거예요.
데이터의 멱등성(정확성)을 해치지 않으면서 비용을 80% 이상 절감할 수 있는 고도의 설계 기법을 정리해 드립니다!
🏛️ 1. 콜드 데이터의 퇴출: "계층형 DW 설계 (Tiered Storage)"
모든 데이터를 하나의 고성능 DW(Redshift, BigQuery 등)에 두는 것은 낭비입니다. 데이터의 활용도에 따라 거처를 옮겨줘야 합니다.
① 핫 데이터(Hot Data): 고성능 DW
- 대상: 최근 1~3개월 데이터, 실시간 분석이 필요한 데이터.
- 전략: 멱등성을 위해 고유 키(PK) 기반의
Upsert를 수행하며, 인덱스를 활용해 빠른 조회가 가능하게 유지합니다.
② 콜드 데이터(Cold Data): 데이터 레이크 (S3 + Parquet)
- 대상: 3개월 이전의 데이터, 가끔씩만 보는 과거 이력.
- 전략: DW에서 데이터를 추출하여 압축률이 극강인 Parquet 포맷으로 S3에 저장합니다.
- 멱등성 유지 비결: S3에 저장할 때 파일명을
데이터_생성날짜_배치번호.parquet형식으로 저장하고, 중복 데이터가 발생하면 파일 단위로 덮어쓰기(Overwrite)를 수행하여 멱등성을 지킵니다.
[Image showing a Tiered Storage architecture: Hot Data in BigQuery/Redshift and Cold Data in S3/Cloud Storage with a transition arrow]
📦 2. 파티션 스와핑(Partition Swapping): "통째로 갈아 끼우기"
멱등성을 유지하면서 비용을 아끼는 가장 세련된 방법입니다.
- 메커니즘: 데이터를 한 행씩
Update하는 것은 DW 입장에서 매우 고비용 작업입니다. 대신, 하루치 데이터를 통째로 '임시 테이블'에서 가공한 뒤, 본 테이블의 해당 날짜 파티션을 통째로 교체(Swap) 해버립니다. - 비용 절감: 행 단위 연산이 없으므로 컴퓨팅 비용이 획기적으로 줄어듭니다.
- 멱등성: 작업이 실패해도 기존 파티션은 유지되므로 데이터가 꼬일 염려가 없고, 재시도하면 새로운 데이터로 다시 통째로 교체되므로 완벽한 멱등성이 보장됩니다.
📉 3. 컬럼형 저장소의 압축 기술 (Columnar Compression)
DW는 대부분 컬럼형 저장소입니다. 이를 최대로 활용하면 비용을 더 아낄 수 있습니다.
① 인코딩 최적화
- Delta Encoding: 주식 가격처럼 연속된 숫자는 앞 숫자와의 '차이'만 저장하여 용량을 대폭 줄입니다.
- Dictionary Encoding: '종목명'처럼 반복되는 문자열은 숫자로 매핑하여 저장합니다. (삼성전자 → 1, SK하이닉스 → 2)
② 멱등성과의 관계
이런 압축 기법들은 DW 내부 엔진이 담당하지만, 우리가 데이터를 전송할 때 미리 정렬(Sort Key)해서 넣어주면 압축 효율이 수 배나 좋아집니다. 같은 종목끼리 묶어서 넣어주면 DW가 "어? 똑같은 거네?" 하고 꽉꽉 눌러 담기 때문이죠.
[Image showing how Row-based storage vs Columnar storage with Delta Encoding reduces storage size]
🏗️ 4. 데이터 레이크하우스(Lakehouse)로의 전환: "DW 없는 DW"
요즘 가장 핫한 트렌드는 "비싼 DW를 아예 안 쓰는 것"입니다.
- Iceberg / Delta Lake: S3 위에 저장된 Parquet 파일에 '테이블처럼 PK를 부여하고 Update/Delete'가 가능하게 만든 기술입니다.
- 장점: 저장 비용은 S3 가격(매우 저렴)인데, 기능은 DW처럼 멱등성을 보장하는
Upsert가 가능합니다. - 효과: 비싼 DW 엔진을 켜두지 않아도 필요할 때만 Athena나 Presto 같은 도구로 S3 데이터를 SQL로 조회할 수 있어 비용을 극한으로 아낄 수 있습니다.
📊 요약: 비용과 멱등성을 다 잡는 4단계 전략
| 단계 | 전략 | 기대 효과 |
|---|---|---|
| 1단계 | Data Aging | 오래된 데이터는 저렴한 S3로 이관 |
| 2단계 | Partition Overwrite | Update 대신 파티션 통째 교체로 멱등성 확보 |
| 3단계 | Zstd/Snappy 압축 | 스토리지 점유 공간 최소화 (최대 70% 절감) |
| 4단계 | Lakehouse 도입 | 고정비(DW 서버) 제거, 사용한 만큼만 지불 |
💡 실전 비유: "백화점과 창고"
- DW: 백화점 진열대. 접근성도 좋고 화려하지만 임대료(저장비)가 비쌉니다. 신상(핫 데이터)만 진열하세요.
- S3: 시외 외곽의 거대한 물류 창고. 임대료가 아주 싸지만 물건을 꺼내오는 데 시간이 좀 걸립니다. 지난 시즌 물건(콜드 데이터)은 압축 포장해서 여기 보관하세요.
- 멱등성: 창고에 물건을 넣을 때 '송장 번호'를 붙이는 것입니다. 같은 송장 번호가 오면 기존 박스를 버리고 새 박스를 넣으면 절대 물건이 섞이지 않죠!
'1. 개발 > 1.4. 데이터 분석' 카테고리의 다른 글
| 실시간 데이터에서 Skew 발생 시 대응 (0) | 2026.02.08 |
|---|---|
| SQL로만 빠르게 분석하고 싶을 때 Athena, Presto (0) | 2026.02.07 |
| '데이터 무결성'을 지키는 최후의 보루, 멱등성(Idempotency) (0) | 2026.02.07 |
| 데이터가 너무 많아질 때 비용을 아끼는 '스토리지 최적화(S3 Tiering, Compression)' 기법 (0) | 2026.02.07 |
| 데이터 리니지(Data Lineage) - 에러 추적 (0) | 2026.02.07 |



