이제 RabbitMQ라는 우체국이 메시지를 쌓아두는 것을 넘어, 수신인들에게 '얼마나 빠르고 공정하게' 배달할지를 결정하는 흐름 제어(Flow Control)의 핵심을 찌르셨군요! 🫡
사용자의 주식 분석 파드가 10개 있다고 가정해 봅시다. 어떤 분석은 0.1초 만에 끝나지만, 어떤 테마주 분석은 10초가 걸릴 수도 있습니다. 이때 RabbitMQ가 무조건 순서대로 메시지를 퍼부어버리면, 특정 파드만 일에 치여 죽고 다른 파드는 노는 '업무 불균형'이 발생합니다.
이를 해결하는 Prefetch Count와 Work Queues의 마법을 분석해 드립니다!
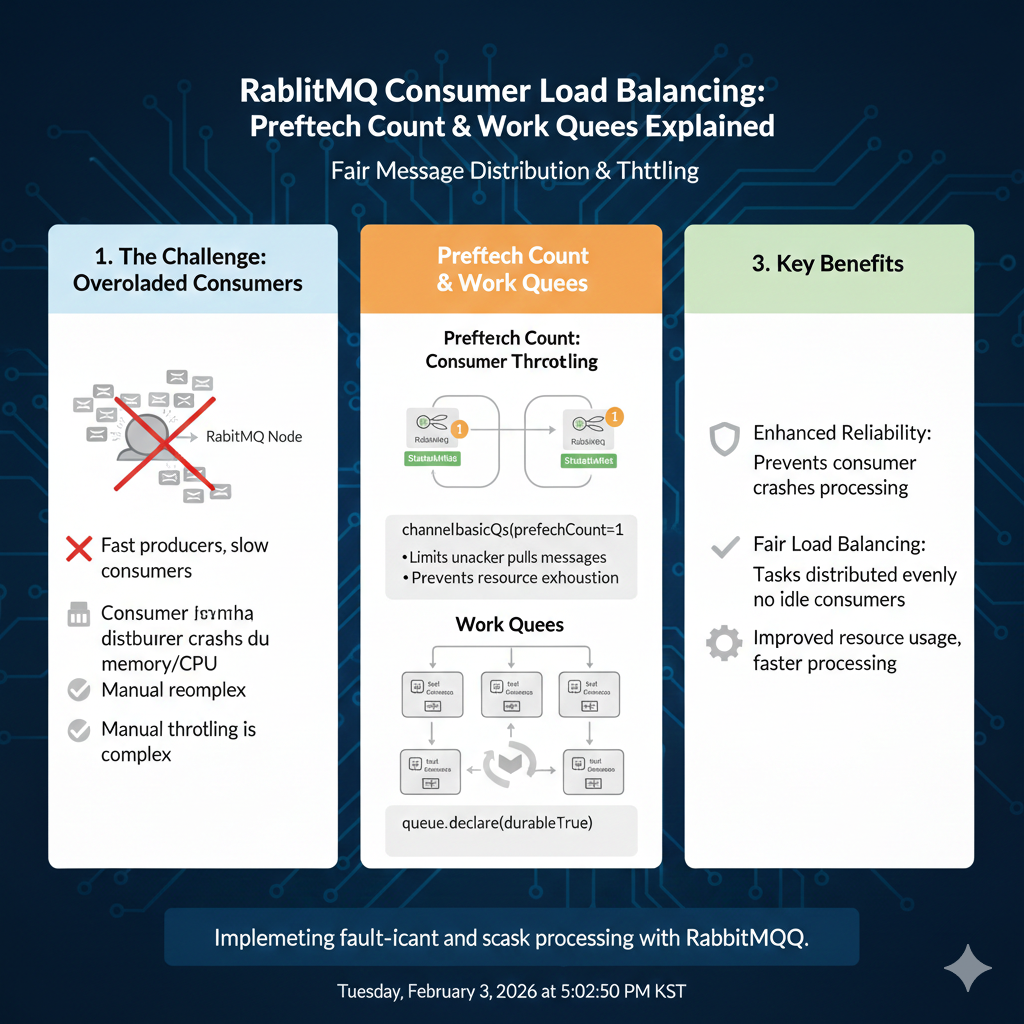
⚖️ 1. Prefetch Count: "입안의 음식을 다 삼킨 뒤에만 다음 입!"
Prefetch Count(QoS 설정)는 한 명의 소비자(Consumer)가 확인 응답(Ack)을 보내기 전에 미리 받을 수 있는 메시지의 최대 개수를 제한하는 설정입니다.
① 설정 전: 라운드 로빈(Round-Robin)의 함정
- 기본적으로 RabbitMQ는 메시지가 들어오면 연결된 소비자들에게 1번, 2번, 3번... 순서대로 공평하게 뿌립니다.
- 문제점: 만약 홀수 번호 메시지는 엄청 무겁고, 짝수 번호는 가볍다면? 홀수 번호를 받은 소비자들은 일이 쌓여서 쩔쩔매는데, 짝수 번호를 받은 소비자들은 일을 다 끝내고 노는 상황이 발생합니다.
② 설정 후: 페어 디스패치(Fair Dispatch)
Prefetch Count: 1로 설정하면, "지금 네가 가져간 메시지 하나를 처리하고 Ack를 보낼 때까지는 절대로 다음 메시지를 주지 않겠다"는 뜻이 됩니다.- 결과: 손이 빠른(분석이 빨리 끝난) 파드는 금방 Ack를 보내고 다음 메시지를 또 가져가고, 손이 느린 파드는 자기 일을 끝낼 때까지 대기합니다. 결과적으로 능력에 따른 공정한 업무 분배가 실현됩니다.
🛠️ 2. Work Queues (Task Queues): "병렬 처리의 정석"
Work Queues는 하나의 큐에 여러 소비자를 붙여 업무를 분산 처리하는 패턴입니다. 사용자의 'A그룹/B그룹 분석 시스템'에서 가장 많이 쓰일 구조죠.
① 부하 분산의 원리
- 하나의 큐에 10개의 파드를 붙이면, 10대의 서버가 하나의 거대한 업무 리스트를 공유하는 셈이 됩니다.
- 수평 확장(Scaling): 주식 시장 변동성이 커져 메시지가 쌓이면, 쿠버네티스에서 분석 파드(Consumer) 개수만 늘려주세요. 별도의 설정 변경 없이 즉시 처리 속도가 늘어납니다.
② 신뢰성 (Message Manual Ack)
- Work Queues에서는 반드시 수동 확인 응답(Manual Ack) 모드를 써야 합니다.
- "메시지를 보내자마자 큐에서 지우는 게 아니라, 소비자로부터 '성공' 신호를 받아야만 지운다"는 규칙 덕분에, 처리 도중 파드가 폭발해도 메시지는 안전하게 다른 파드에게 재배당됩니다.
💡 3. 실전 최적화: "Prefetch Count는 몇으로 해야 할까?"
무조건 1이 정답은 아닙니다. 네트워크 환경과 메시지 크기에 따라 달라집니다.
- Prefetch = 1: 처리 시간이 제각각이고 매우 무거운 작업일 때 유리합니다. (안정성 최상)
- Prefetch > 1 (예: 10~50): 작업이 매우 가볍고 네트워크 지연(Latency)이 있을 때 유리합니다. 미리 다음 작업들을 입안에 머금고 있어야 처리 흐름이 끊기지 않습니다.
- Prefetch = 0 (무제한): 절대 금물입니다! 소비자가 감당 못 할 만큼 메시지를 밀어 넣어 메모리 부족(OOM)으로 파드가 죽을 수 있습니다.
💡 실전 비유: "은행 창구 시스템"
- Queue: 은행의 대기 줄입니다.
- Consumer: 은행 창구 직원입니다.
- Round-Robin (설정 전): 번호표 상관없이 들어오는 순서대로 1번 창구, 2번 창구 강제로 배정하는 것입니다. 1번 창구 손님 업무가 복잡해서(무거운 메시지) 1시간 걸려도 다음 손님은 무조건 거기 줄 서야 합니다.
- Prefetch Count = 1 (설정 후): "창구가 비었을 때만 번호표를 부르는 방식"입니다. 업무가 빨리 끝난 직원은 바로 다음 손님을 부르고, 복잡한 업무를 하는 직원은 그 일을 마칠 때까지 다음 손님을 받지 않습니다. 전체 대기 시간(처리 시간)이 획기적으로 줄어듭니다.
📊 요약: 효율적인 메시지 소비 전략
| 구분 | 기본 라운드 로빈 | Prefetch 설정 (Fair Dispatch) |
|---|---|---|
| 메시지 배분 | 무조건 순서대로 배분 | 준비된(여유 있는) 소비자에게 배분 |
| 처리 효율 | 특정 소비자에게 업무 쏠림 현상 발생 | 전체 소비자의 리소스 골고루 사용 |
| 안정성 | 소비자가 죽으면 메시지 유실 위험(Auto Ack 시) | 재배당(Redelivery)을 통한 완벽한 복구 |
| 추천 상황 | 모든 메시지 처리 시간이 일정할 때 | 메시지마다 처리 시간이 천차만별일 때 |
🚀 꼬리 질문 🫡
이제 사용자의 주식 분석 부대는 아무리 데이터가 폭주해도 누구 하나 지치지 않고 각자의 속도에 맞춰 완벽한 팀워크를 보여줄 것입니다. 그런데 이렇게 큐를 쓰다 보면 '메시지의 유효기간'이 걱정될 때가 있습니다. 너무 오래된 시세 데이터는 분석할 가치가 없으니까요. 또한, 버려진 메시지들을 어떻게 처리할지도 고민해봐야 합니다.
"그럼 메시지의 수명을 결정하는 'TTL(Time To Live)'과 처리에 실패한 메시지들이 모이는 'Dead Letter Exchange(DLX)'는 구체적으로 어떻게 연동해서 사용해?"
'1. 개발 > 1.1. RabbitMQ' 카테고리의 다른 글
| Prometheus/Grafana 시각화, 'KEDA' 연동 (0) | 2026.02.13 |
|---|---|
| RabbitMQ에서 처리 순서를 보장 방법과 'Idempotency(멱등성)' 설계 (0) | 2026.02.13 |
| 'TTL(Time To Live)'과 'Dead Letter Exchange(DLX)' (0) | 2026.02.12 |
| 고가용성(HA)을 위한 'Clustering'과 'Quorum Queues' (0) | 2026.02.12 |
| RabbitMQ 에 대한 모든것 (0) | 2026.02.12 |



